|
The actual process of designing and developing software is complex. In this section you will look at different aspects of that process as it applied to the Power project.
Getting started
Defining and understanding the problem
Before any kind of research project starts, it needs:
- people to generate the project concept
- a focus problem that the project tries to solve.
In this case the people who generated the project concept were Robert Dale and Cécile Paris. The focus problem was that when you currently access databases, the information you retrieve may not quite be what you need. For example, if you search the Internet, you get a vast array of information; but without reading it all, it is difficult to assess its suitability. By using natural language generation technologies and applying them to this problem of more effectively presenting information, the search for information can be more effective and more tailored to user's needs.
The research team
Once Robert Dale and Cécile Paris had decided what the project was going to be, the next step was to put together the team to do the research.
Funding
Of course, a great project and a great team add up to nothing if there's no money to pay for it. So how does research get funded? Funding can come from a number of sources, including governments, industry, universities, research organisations such as the Australian Research Council and cooperative research centres (CRCs). For information on specific CRCs, click here.
Currently, however, research is generally carried out in partnerships. Sometimes an organisation has a research budget, and decides to use some of that money on a particular project. Other times researchers come up with a project, then try to get funding for it from their institution, from industry, or from the Government.
With the Power project the money came first. When the project began, the Centre for Language Technology was the Microsoft Research Institute for Advanced Software Technology, which was part funded by Microsoft Australia. Robert Dale was the director of the Institute:
We had a body of funds that funded our research lab, says Dale. It meant we had some staff who would work on projects that we specified, and we decided this was one of the projects they would work on.
Selecting a database
One of the goals of the project was to design a way of generating hypertext documents from a database. The team decided that the best way to develop software to do this was to take a real database that already existed.
The team decided to collaborate with the Powerhouse Museum, Sydney, using the Museum's database. The idea for using a museum came partly out of earlier research done in Britain.
There was a project in Edinburgh called the ILEX project. This was done in conjunction with the Scottish Museum in Edinburgh. The idea was to build a system where, instead of having curators write labels for objects, we could have a machine write labels for objects. The perceived benefit of this was that if the machine was writing labels then it could write a lot more of them than people could. And so in particular, if you wanted the labels to be different, depending on, for example, who read them, for an example, their age, or where they came from, then you could do that. If you wanted the labels to somehow be linked in terms of the history of objects that the visitor had seen or the objects they might see, then again the machine could do this in a much more flexible way given the combination of objects. The machine could do things in a personalised way that a human curator might be able to do wouldn't have the time to do.
One of the team members, Maria Milosavljevic, had already built a system called PEBA-II that described animals in an encyclopedic context. Maria's system can compare animals as well as describe them, and then generate a page that takes into account the user's level of knowledge, what other pages the user has had just looked at and so on.
ILEX and PEBA-II were the sources of the ideas that the Power project wanted to build on. Robert and Cécile decided that they could add some of the ideas from PEBA-II to a system like ILEX.
Robert: We thought... we may as well go for a museum context. It's a nice one to do... You have:
- objects which have lots of interesting properties, and usually there are quite rich ways of describing those objects;
- lots of objects; and
- often pictures of the objects too.
And so there's scope for having interacting text and graphics in terms of presenting these things.
Cécile continues: So in terms of objects and their description, this was a bit similar to PEBA... The Powerhouse was a similar type of domain. There was the potential of having the data, and lots of it in different areas from textiles to musical instruments to robotics to informatics. And there was the potential that people couldn't produce these kinds of descriptions by hand. I mean, there would be too many combinations; you have different people going to visit museums with different backgrounds and different ages and different interests. So there was this richness of trying to produce something appropriate for the user, which is one of the big things we are looking at as well.
A museum would give the project the right sort of data with the right sort of structure and the right sort of audience to test it on.
We had lots of ideas and we had a number of brainstorming meetings where we tried to think of functionalities that we thought would be useful to have in the context of a text generation system for a museum, says Robert.
Cécile continues: I think we chose a museum as a good application, not just for a prototype. In the museum domain there is also the potential to have a real system we could run on the web, which would then give the museum visibility anywhere. So wherever the actual museum is, people could have a virtual tour.
Another reason for choosing the Powerhouse Museum was because the Powerhouse is concerned with information technology, so the team thought they would be interested in being involved.
We had lots of ideas for things, says Robert. Like how you might have people visit the museum on the web, and have these dynamically generated descriptions of objects and so on. They might, as a consequence of this, identify some sub-set of objects that they're interested in — with a kind of shopping - basket - on - the - web metaphor — and they collect them. Then when they actually come to visit the museum, perhaps they get a personalised itinerary printed out that shows them the real objects.
Cécile's prediction was right. The IT curators were very interested in the project, and agreed to collaborate. The Dynamic Document Delivery project would work with the Powerhouse database, and the project became the Power project.
Planning
Planning and designing the software solution
Once a research team has been put together, the funding has been organised, and the goals of the project are clear, the project is ready to be started. But before anything can happen there has to be a plan. The question is, how detailed does the planning need to be?
There are two forces at work. If a research project is going to have a hope of reaching its goals it has to be planned, so the work stays focused on the goals. But because research like this involves doing something new, there are always going to be unexpected problems or advances, and directions will open up that couldn't be seen beforehand.
So how are these two forces balanced? What approach did the Power project take? Did they work out exactly what they were going to do before hand?
I'm not sure quite how this relates to good practice, it's like a "do what I say and not what I do" sort of thing, says Robert Dale. I was a software engineer in a previous existence. I was very much brought up, taught, with a very kind of top - down design methodology. If you want to solve a problem, you sit down, you analyse the problem, and then you build a design for a solution to that problem, top - down. So you go through a requirements specification stage, you do a functional specification, you do a top - level design, and then you do a detailed design. It's all very structured.
Generally, when you're doing research projects, that isn't how things work. You can try to impose that kind of structure — in fact I generally do try to impose that kind of structure on these projects — but invariably it doesn't work. And it doesn't work because it's research. You find out, well actually you can't do this thing you set out to do, or it's too difficult to do something in the way you had planned, or it's easier a different way, or in fact maybe there's a more interesting question over in this corner we didn't think about before. So it's very hard to do run this in a project-managed sense.
We had a number of meetings early on with all the team where we tried to flesh out the design from various perspectives, but we never, at any point, had a full design specification.
Choosing a programming language
An important question when you build a sophisticated software application is: what programming language should you use? There are hundreds of programming languages, and they all have advantages and disadvantages, depending on what it is that you want to do. Some languages are good for some things, and others are good for other things. Of course, in a research project, you never quite know at the outset exactly what you'll need to do, so that makes choosing a language even harder.
All programming languages provide abstractions. It can be argued that the complexity of the problems you can solve is directly related to the kind and quality of abstraction. By "kind" I mean: what is it you are abstracting? Assembly language is a small abstraction of the underlying machine. Many so-called "imperative" languages that followed (like FORTRAN, BASIC, and C) were abstractions of assembly language. These languages are big improvements over assembly language, but their primary abstraction still requires you to think in terms of the structure of the computer rather than the structure of the problem you are trying to solve. The programmer is required to establish the association between the machine model (in the "solution space") and the model of the problem that is actually being solved (in the "problem space"). The effort required to perform this mapping, and the fact that it is extrinsic to the programming language, produces programs that are difficult to write and expensive to maintain, and as a side effect created the entire "programming methods" industry.
The alternative to modelling the machine is to model the problem you're trying to solve. Early languages like LISP and APL chose particular views of the world ("all problems are ultimately lists" or "all problems are mathematical"). PROLOG casts all problems into chains of decisions. Languages have been created for constraint-based programming and for programming exclusively by manipulating graphical symbols (the latter proved to be too restrictive). Each of these approaches is a good solution to the particular class of problem they're designed to solve, but when you step outside of that domain they become awkward.
The object-oriented approach takes a further step by providing tools for the programmer to represent elements in the problem space. This representation is general enough that the programmer is not constrained to any particular type of problem. We refer to the elements in the problem space and their representations in the solution space as "objects" (of course, you will also need other objects that don't have problem-space analogs). The idea is that the program is allowed to adapt itself to the lingo of the problem by adding new types of objects, so when you read the code describing the solution, you're reading words that also express the problem. This is a more flexible and powerful language abstraction than what we've had before.
There's still a connection back to the computer, though. Each object looks quite a bit like a little computer: it has a state, and it has operations you can ask it to perform. However, this doesn't seem like such a bad analogy to objects in the real world: they all have characteristics and behavior. Extract from Eckel, B. (1996) Thinking in Java , Chapter 1: Introduction to objects, http://www.sce.carleton.ca/netmanage/java/thinking/chap1.htm
Activity Predict the type of programming language that would need to be used:
- declarative
- functional
- object oriented.
What programming languages did the project use?
We built it, all the system, from the ground up, says Robert Dale, and we used a programming language called LISP. I think we used one software component from elsewhere, a piece of software that a lot of people have used which does some of the fine-tuning grammatical work in producing sentences, so we used that for some things. We now think it was overkill for the things we had to do, but it was available at the time so we used it. But most of what was there, we had to build.
But there were two main problems with LISP.
Programming languages are all different and they're good at certain things. One of the problems with LISP is that it's seen as what you might think of as a heavy weight language. Typically it has a big cost in terms of running it, but although it's getting better. Also it's not widely taught, so there are relatively few programmers around.
Because the software got so big at the beginning of 2001 the team tried to completely rebuild the system.
Activity LISP is a functional language. What are the advantages and disadvantages of using a functional language.
Developing and designing
The goals of the project were:
- to work out ways to dynamically generate documents that vary to suit the user's needs
- to design and develop an architecture to dynamically generate on-line hypertext documents
- to work out ways of dynamically generating documents in different languages
- to find a way of automatically converting information from existing databases into a form that could be utilised by the natural language software.
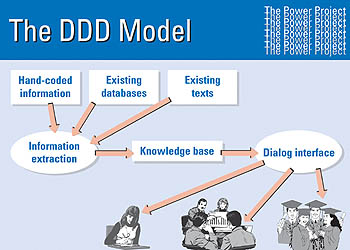
The components of the system
The project set out to build the Power system, which would dynamically generate web pages about objects in the Powerhouse Museum directly from the Museum's database.
For this to work, the system needed four basic components:
- a component that decides what content from the database has to be expressed
- a text structuring component that organises the information into a text plan
- a component that turns the information into natural language
- a document renderer, for creating HTML-specific annotations.
For the system to work it needed a system architecture that would integrate the components and also allow the user to interact with the system.
The job of the research team was to design each of these components and the architecture that would fit them together so the whole system would work.
The existing databases for the boots for example contained:
|
Putting the plan into action
The next step was to clarify who would be responsible for various tasks. The work was divided between the team members. Everyone went away and worked on their tasks separately. Robert Dale explains:
We fleshed out the basic architecture in meetings, and one or other member of the team would be responsible for putting the basic architecture together. But then the main bulk of the work was in the pieces that slotted into that architecture, and typically one individual would take on one piece, one module if you like.
We knew roughly the goal we wanted to reach with the system, and we made design decisions, in terms of the technologies we'd use. As a group, we'd sit down and say, "well, we could do it this way". We'd argue about this, and someone would point out that if you do it this way there's a certain problem and so there's always trade-offs. So we'd have to make decisions about what was the most effective solution, even if it was sub-optimal, as sometimes the most effective solution would be. And so we established what technologies we wanted to use, and then we apportioned the implementation of some of these pieces.
Activity
Predict what needed to be done and who would complete the tasks.
Each individual on the team had some pieces they were working on.
Steve Green's main part in the implementation was to take the underlying data from the museum and find a way of sucking stuff out of it that we could use, so that was his key thing.
Maria worked on organising the text that the system created so that it was fluent text that we produced.
Karen would go away and make sure that all the linguistic resources for Dutch were there, and Cécile would make sure that all the linguistic resources for French were there. We had another Stephen, Stephen Wan, who came for a summer and added Chinese to the system.
Activity
Depending on what subject you are studying draw one of the following diagrams:
- system flowchart
- data flow diagram
- IPO
- storyboard.
Working together
The team met regularly. How often they met varied depending on the level of activity in the project, but during the main period of the project they would meet once every one or two weeks.
And how much time did each of the team members devote to this project, and how much did they have to put into other unrelated projects?
Basically, Karen and Steve were allocated 50% of their time to the project. I was something like nominally a day a week, half a day a week or something, as was Cécile. Maria's contribution fluctuated depending on pressures in CSIRO and what other projects she had on and so on. That period of development went on for quite a while, it could easily have been a year, maybe more.
Did the people in the team always get on?
Occasionally, some people may have felt that they didn't get credit for certain things and stuff like that, but that happens in every team. By and large I think it was a happy family. It was a fairly small team, so that really had some bearing on that. But yes, there were no great upsets at all. Also, we had a couple of team members who were really good with the social dynamics side of things - I think that made all the difference.
Implementing and modifying
Building a first prototype
The first step in building the system using the Powerhouse Museum database was to build a very small version incorporating some of the features the team was aiming to develop. In other words, they built a prototype or a model.
The PEBA-II system used many of the ideas that would be carried over into the Power project. It generates descriptions of animals, and it compares them, with the facility to factor in the user's level of knowledge. This formed the starting point for the Power prototype.
The team's computer programming specialist, Steve Green, along with Karen Verspoor and PEBA-II's original designer Maria Milosavljevic, took the PEBA-II system and redesigned it to work with items from the Powerhouse Museum collection.
Steve very quickly re-engineered the PEBA system. He took the PEBA system as it existed — the system that provided encyclopaedic descriptions of animals — and very quickly converted it, making some changes to some of the components, into a system that would describe museum objects. For that purpose we had a very small knowledge base or database of something like 10, 15, 20 objects in the domain of computing. The database was created by hand. And so this little system, which still runs on the web will make descriptions slightly different in each case and so on. In fact, you can visit and you can ask about particular objects and get descriptions of objects and you can see whether you're a naive user or an expert user. We built this demo fairly quickly and then we took it to the Powerhouse to show the IT curators and everyone seemed quite interested.
To look at the demo, click here.
However building a system for generating web pages was only one of the project's goals. For the prototype a special database was written specifically for the system. But the project's main goals were to design a system that could take information out of large databases that already exist, and turn that information into dynamically generated documents.
Our real goal was to get to real data, says Robert Dale, because the data set underlying this very simple prototype was all hand constructed, and that's as bad as having to write the text. It's probably worse, in fact, because you have to be very, very rigid and follow particular structures in producing the data. What we really wanted to do was to take real data that already exists in, for example, a collection management system, or a collection information system, and somehow convert that automatically into something we can use.
The next step was to try and make the system work with a database that already existed. But how does an expanded system develop out of the prototype? Do you add to the prototype, or start from scratch?
Activity
Discuss the advantages and disadvantages of developing a prototype.
Rebuilding the system
The team decided to start from scratch and avoid the pitfalls of expanding the prototype.
Often what happens is it's only a prototype, says Robert Dale, and people say "we'll rewrite it next month, next year, next decade", and the prototype lives on. It often happens. "Let's just extend the prototype." In fact I've been involved in a project with some outside concerns where exactly this is happening. Everyone in the design team is saying "if you want to scale this up to a larger set of data, it's got to be rebuilt from the ground up". But the management keeps saying, "oh just add this little bit, add this little bit, add this little bit". It's a mess.
Prototype 2
The prototype the team built used data from a database that had been specially written by hand to support the document generation. To move the research to the next stage the team had to make the system work with real data from an existing database.
They went back to the Powerhouse Museum and gained access to an initial sample of data for about a thousand items in the Museum's collection.
Robert: It was the most recent additions to the catalogue basically, and we put quite a lot of effort into trying to extract information out of the database into a form that we could use.
This became a major research area for us; just converting the data to something we could use.
Cécile: It was not like the data was there for us to take and immediately put the technology on the front of. We had to do something to the data first.
The problem was how to get meaningful data out of a database that was not structured in a way that made that easy. The data in the Museum database had been put in at different times by different people, and was designed to allow the curators to keep records about what was in their collection. It was not a system designed to support text generation.
Cécile: We expected that. We knew that was going to be the case and we went into this project wanting to address that particular issue. Robert and I, that has been one of our interests in the past, recognising that access to that data is really important. It is the key to technology and is currently one of the problems with some of the technology, I mean if you have to manipulate the data by hand you might as well write the text, so that's very hard.
Robert continues, if we had only wanted a small prototype system we could have stopped at 15 objects, but the reason we went to the whole project is because we really wanted to have real data, and see what we could do with it.
Knowledge base
Now the project focused on the knowledge base, the data that underlies the whole system. Here's a diagram of the system architecture the team were trying to build.
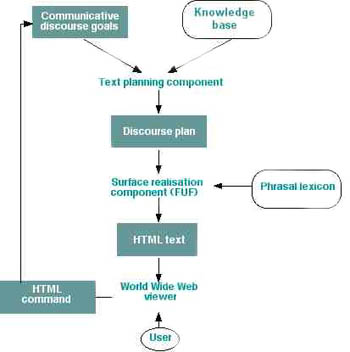
Dynamic hypertext architecture |
Activity
Define the term knowledge base.
The data, or knowledge base as it's called here, looks like a small part of the whole system, so why was it such a big focus? Because most previous research had focused on how to get the data out and generate texts from it, and not on the problems that come with handling real data. Robert Dale explains.
Historically what's happened in our field is that people have been so driven to finding solutions to the other boxes in this diagram, that the knowledge base tends to be ignored. So the question of "what knowledge does your system have and where does it come from" is one that is kind of relegated to, "well those guys down the corridor will do that". Which guys down the corridor? They're not there any more, they've gone . But it has to get done. So we chose to be the guys down the corridor.
And so that's why we are very interested in the Powerhouse Museum's information system, because we thought : here's an opportunity to see what it's like to take a large existing data set and see if we can do something useful with it.
Cécile adds: We thought it was a really interesting problem and that it was a crucial problem to make the technology actually practical and to be able to transfer it then to a real world, as opposed to just researched prototypes. Historically people have ignored that problem, and it's precisely for that reason that a lot of this research has never left the research lab.
Outcomes
So what kinds of descriptions did the Power system end up managing to generate out of the Powerhouse Museum's real database? After the Power team had built two prototypes, they moved on to a much bigger database. They tried to make the Power system generate descriptions from the Powerhouse Museum's collection information database on 15 000 objects.
Technically it worked. But how good were the descriptions?
We could lay claim to having the broadest coverage generation system on the planet, Robert Dale says. At that time, no-one had attempted natural language generation using a database of that size. We ended up with a system that could describe 15 000 different objects. However, it didn't necessarily mean the descriptions were good.
When we say that the descriptions were not good, explains Cécile Paris, they used quite coherent patterns for English, but they were not very interesting. For example, the system would say:
"this is a table made of wood and it's got however many legs it has and it was manufactured by whoever"
So it just gave some of the attributes that we could get from the data, but as a result the descriptions were not particularly interesting.
You couldn't give the history of the table that you got from your grandad or something. That's all the interesting stuff, but it's stuff that wasn't present in the database. The descriptions were perfectly fine grammatically; they were just boring.
The problem was that some of the data in the database wasn't very rich. Some entries had lots of interesting information, and some didn't. The team did a pilot study using data from the Museum's collection of 300 or 400 shoes. These were very well documented because they'd recently been on display, and the descriptions the system generated from this data were interesting. But with the rest of the 15 000 objects, the descriptions varied. Click here to find out more.
Testing and evaluating
Developing software is one thing, but can people actually use it? The way to find out is to test it. Before the development process of any new product or service is finished it needs to go through a series of tests to make sure it does what it's supposed to do, and software is no exception. However the Power project has not reached the finished product stage. So how far did the Power project get along that road, and what testing was done?
Like PEBA-II, a trial version of the Power system was placed on the web. The idea was that people would discover the site and play with it, and give the project team feedback. And that's exactly what happened. Robert Dale explains the team's thoughts about testing for this project:
We didn't do any formal evaluation because I don't think that we got to a stage where we wanted to subject it to formal evaluation. We always felt we had a bit more to do. But simply by virtue of the fact that the systems were on the web, people would send us comments, so we did get feedback from people about things. Although you would get funny feedback... messages like "are you sure that boot is really that size?" ...So we didn't go through a formal evaluation thing, but that wouldn't have made sense.
We had curators from the Powerhouse Museum come and look at a version of it one time but it was still in a state we weren't very happy with.
Certainly if one wanted to put this kind of thing on the streets then you would go for a much more structured process of evaluating what was there, but you would also go through a much more end-user-driven requirements analysis process as well. So we were interested in balancing on the one hand doing something useful, but at the same time exploring certain research ideas we had. And those two things may sometimes be in conflict.
Activity
Consider the good and bad aspects of this software design development. What would you do differently?
Reflecting
Looking back, the project leaders thought about what overall problems they had faced, and what issues remained unresolved.
Two big issues stood out. One was to do with data quality. The other was a practical problem to do with running a research team.
Data quality
The really big technical problem the team faced was dealing with the quality of data in the database:
...the conclusion we came to was, it really depends on the data, and if the data isn't wonderfully clean, then you actually have a can of worms that opens when you try to deal with the data. (Dale)
But that won't stop future research.
We've thought about that several times, because we know there's a lot of movement now towards XML encoding of museum information and stuff like that. So we'd like to look into that, and part of the reason for our reconstruction was to give us a platform that we could sink other knowledge bases and databases into, so that was all part of that picture.
But to start with we were very naive about what was in the data. And even if the data had been clean, the system doesn't provide some of the interpretation that a curator would provide... There are problems in using that information and manipulating it, but our general concern has been: can we get higher quality data? Our suspicion is most real data sets are like this actually when you get down to it.
The problem with databases is finding a way of putting the data in so it meets all possible requirements. When databases are designed they're usually designed so it's easy to put data in, and so it answers the questions the people who put the data in might want to get out later. Less thought is usually given to other people who might want to use it later, and what they might use it for.
So, after all the work that was put into the project, where does the research go next?
What Cécile and I have been concerned to do, says Robert, is not to lose that investment, and to get it back return it to a state where we can use it for other things. The basic infrastructure we have, in theory, can be used for describing anything. There's a general platform there, but it's kind of tailored a bit towards the kinds of things we do in the museum, so that is still there and we have thought about trying to put in other data sets.
Running a research team
One of the biggest problems the project faced was losing its staff. When people move on, a lot of the knowledge they've developed goes with them. And even while the project was under way many of the staff had other pressures on their time.
Activity
Suggest how the problem of losing staff could be resolved.
Another more minor ongoing issue is finding a balance between the research agenda and a usable end result.
Achieving a balance
One issue that remained through the project was finding the balance between designing something functional on the one hand, and using research to push the boundaries and investigate problems in software design on the other.
Robert: To be frank, we think that we could probably have sold the work better than we did. We could probably have found ways to entice outside interest better than we did by focusing the objectives a bit more in certain ways. So we were still driven by a research agenda rather than the functional utility agenda, which is in a way kind of right for a research lab.
But I think many research labs have realised that we have to change that orientation a little bit. So I think we'd have done things differently if we had thought about that a little bit more and we'd have had different results that would be better in some ways and not so good in others ways as a consequence of that.
Activity
Suggest strategies to improve the balance between the research agenda and a useable end result.
|